


How Fast Does the Jetson Nano Really Run Large Language Models?

Last Update: Jan 16, 2025

AI changed software development. This is how the pros use it.
Written for working developers, Coding with AI goes beyond hype to show how AI fits into real production workflows. Learn how to integrate AI into Python projects, avoid hallucinations, refactor safely, generate tests and docs, and reclaim hours of development time—using techniques tested in real-world projects.
There’s been a lot of talk in social media about the new Jetson Orin Nano, and I’ve contributed my fair share. But what’s the performance really like? To find out, I ran Ollama and tested 20 different models, checking their speed. I used a prompt that would produce a long result, and I’ve listed the timings below.
Note: I have updated all these tests. They were originally run in 7W mode, these tests are in 25W mode, showing the full capabilities of the device.
I recieved several DMs with questions about this, so I ran some extensive tests to answer them. These tests aren’t flawless, but they give a good sense of your favorite model’s performance. We’re only testing models up to 4b, as larger ones don’t run well on this Jetson.
Let’s do this. If you want to replicate these tests, here’s how to set up your Jetson Orin Nano to run them.
Setting up Jetson Containers
Jetson containers create a simple, isolated space for AI/ML apps on NVIDIA Jetson platforms. They make managing dependencies easy, ensuring uniform performance, and speeding up prototyping and deployment.
They package your app and its libraries into a single, self-contained unit, making it easier to share, reproduce, and deploy your work on various Jetson devices.
Huge shoutout to Dustin Franklin for his work. He’s a principal engineer at NVIDIA and has built a ton of great tools for working with the Jetson.
I used his Jetson Containers tool to create a container with Ollama to run these tests. If you want to do the same, follow these instructions:
Clone the repository:
git clone https://github.com/dusty-nv/jetson-containers && cd jetson-containers
Install the tools:
sudo bash install.sh
This script will set up necessary Python requirements and add useful tools like autotag to your system’s path.
Installing Ollama
Ollama is designed to run within a container, which makes the installation process cleaner and ensures compatibility. Here’s how to do it using the jetson-containers tools:
1. Run the Ollama container
The jetson-containers repository provides a convenient way to launch Ollama. Use the following command:
jetson-containers run $(autotag ollama)
Note:
-
autotag ollamaautomatically determines the correct Ollama container image based on your Jetson’s JetPack version. -
jetson-containers runpulls the image (if it’s not already present) and starts the container.
You should see something like this:
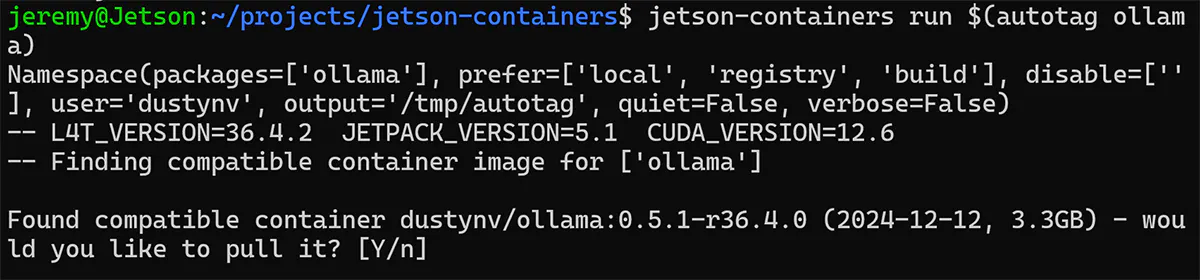
Select yes, and start pulling the image. If successful it should look like this:
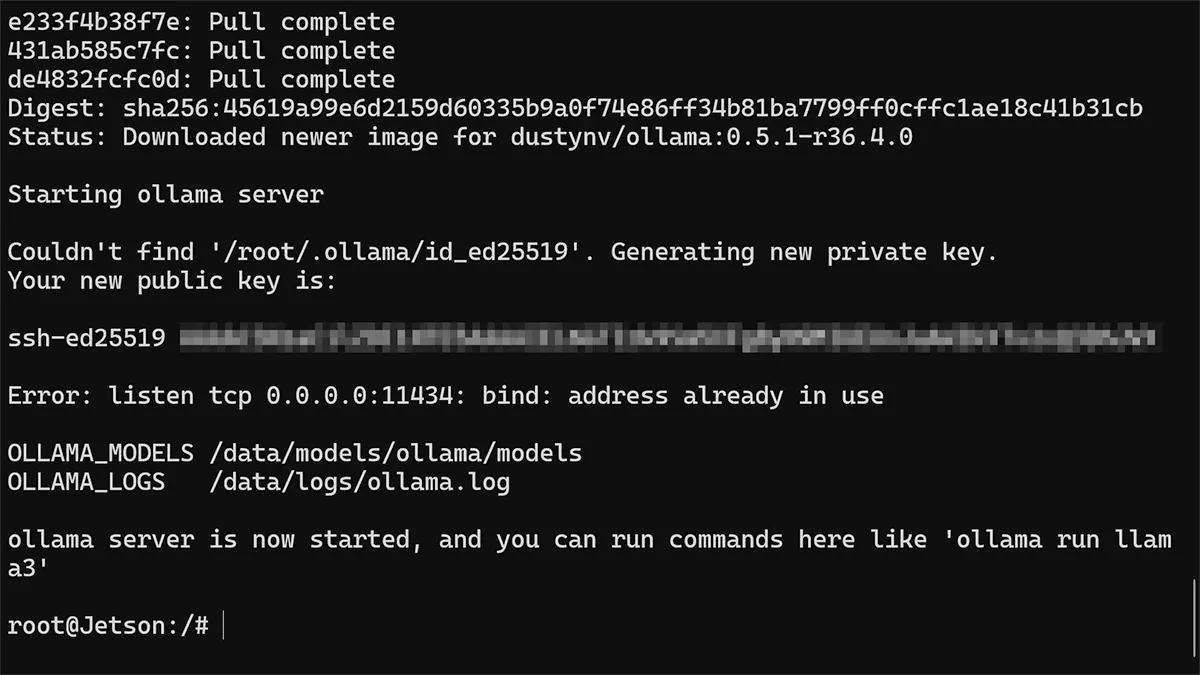
You should now be dumped into a running docker container. You can log into another terminal and verify by running
sudo docker ps

- Access Ollama: Once the container is running, you can interact with Ollama. Typically, Ollama provides a web interface or an API. The specific instructions for accessing this will depend on the version of Ollama you’re using. Check the Ollama documentation or the output of the container logs for details.
Important Notes:
- JetPack Version: The compatibility of Ollama and the container images depends on your Jetson’s JetPack version. Make sure your JetPack version is supported by the
jetson-containersrepository and Ollama. - Storage: Ollama can require significant storage space for its models. Ensure you have enough free space on your Jetson’s storage. Consider using an NVMe SSD for better performance.
- Memory: Running large language models like those used with Ollama can be memory-intensive. Monitor your Jetson’s memory usage and consider using swap space if necessary.
- Documentation: For the most up-to-date and specific instructions, always refer to the official documentation for
jetson-containersand Ollama.
So, if you have a Jetson and want to do your own tests (or use Ollama), that’s the best way. It only takes a few minutes. Now, let’s look at the tests I ran.
How and What I Tested
I thought I’d download a bunch of models that you run on a Jetson Orin Nano. Some run very fast, and some not so fast, but there are a ton of different workable models you can use.
Here are the models I have installed that we’ll test today:
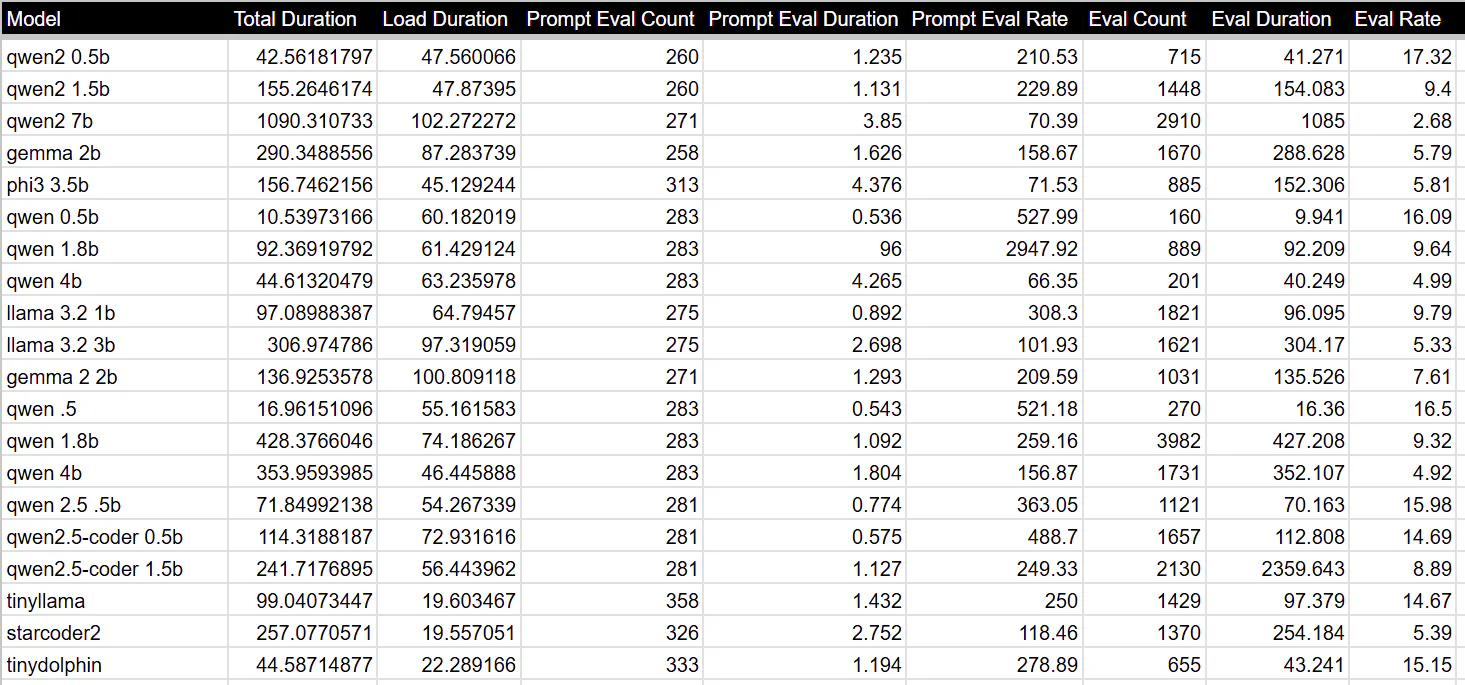
Here’s how I will test them. I’ll send the following prompt, which is sure generate a nice long answer:
Write a comprehensive technical article (approximately 5000 words) on the evolution of deep learning architectures for natural language processing (NLP) tasks.
Include the following:
- A detailed historical overview: Starting from early neural networks like perceptrons, trace the development of key architectures like recurrent neural networks (RNNs), long short-term memory (LSTM) networks, gated recurrent units (GRUs), convolutional neural networks (CNNs) for text, and transformers (including attention mechanisms).
- A discussion of key breakthroughs: Analyze significant advancements such as word embeddings (Word2Vec, GloVe, FastText), attention mechanisms (self-attention, multi-head attention), and pre-trained language models (BERT, GPT, XLNet).
- An exploration of current trends: Discuss emerging research areas like graph neural networks for NLP, few-shot learning, and the role of unsupervised learning in NLP.
- A critical analysis: Evaluate the strengths and weaknesses of different architectures, discuss their impact on various NLP tasks (e.g., machine translation, sentiment analysis, question answering), and analyze the challenges and future directions of deep learning in NLP.
- A comprehensive bibliography: Include a list of relevant academic papers and publications.
I’ll use the same prompt for consistency. Remember that large language models are not deterministic, so they will generate a different number of tokens, but this should get us close.
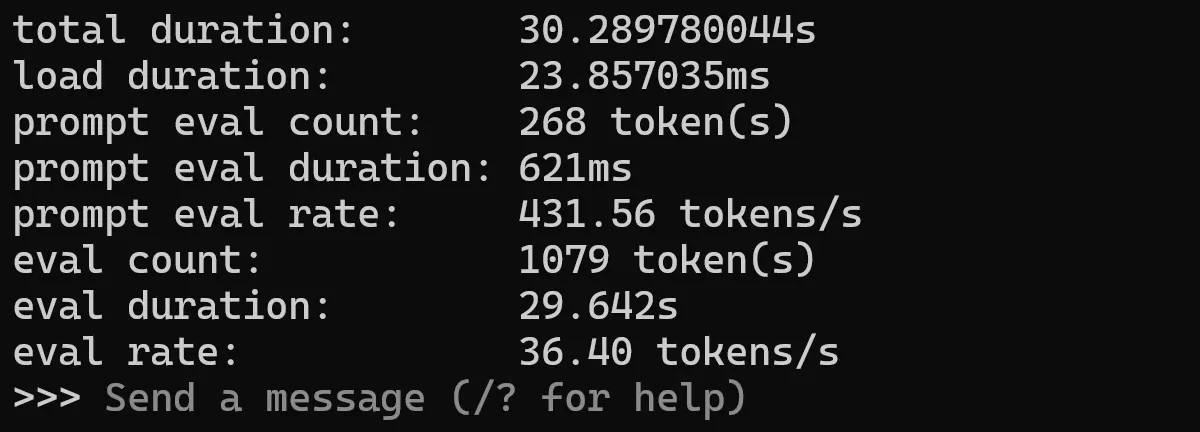
I will then run each model in verbose mode in Ollama:
ollama run qwen2:0.5b --verbose
It will then output something like this:
Qwen 2 0.5b results
| Metric | Value |
|---|---|
| Total Duration | 34.56670174s |
| Load Duration | 59.683175ms |
| Prompt Eval Count | 260 tokens |
| Prompt Eval Duration | 302ms |
| Prompt Eval Rate | 860.93 tokens/s |
| Eval Count | 1535 token(s) |
| Eval Duration | 34.202s |
| Eval Rate | 44.88 tokens/s |
But what does this mean? Here’s a breakdown:
- Total Duration: The total time it took the model to complete the task. This includes all processing time.
- Load Duration: The model’s time to load or initialize before starting the task.
- Prompt Eval Count: The number of tokens (individual words or sub-word units) in the input prompt given to the model.
- Prompt Eval Duration: The model’s time to process and understand the input prompt.
- Prompt Eval Rate: The speed at which the model processed the input prompt, measured in tokens per second.
- Eval Count: The total number of tokens the model processes during the entire task, including both the prompt and the generated output.
- Eval Duration: The model’s time to process all the tokens during the task.
- Eval Rate: The overall processing speed of the model during the task, measured in tokens per second.
This should give us a good idea of how fast the Jetson Orin Nano can handle models with Ollama. Let’s dive in!
QWEN2 Models
Qwen2 is a new series of large language models from Alibaba group.
QWEN2 0.5b
Let’s start with Qwen2 0.5b. This should be a fast one:
ollama run qwen2:0.5b --verbose
t
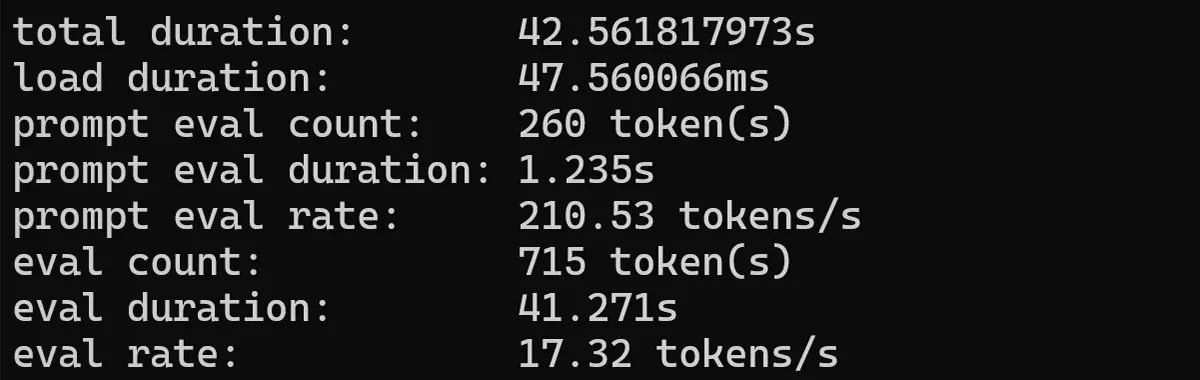
Not bad at all! This is decent speed, and great for a model this size.
Let’s go with a bigger model.
QWEN2 1.5b
ollama run qwen2:1.5b --verbose
This one was a bit slower, as expected. Still usable in many cases.
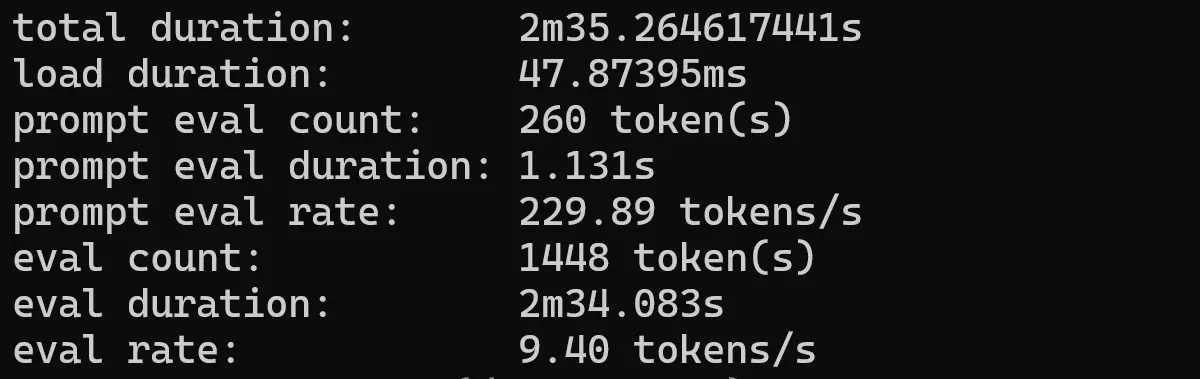
QUEN2 7b
ollama run qwen2:7b --verbose
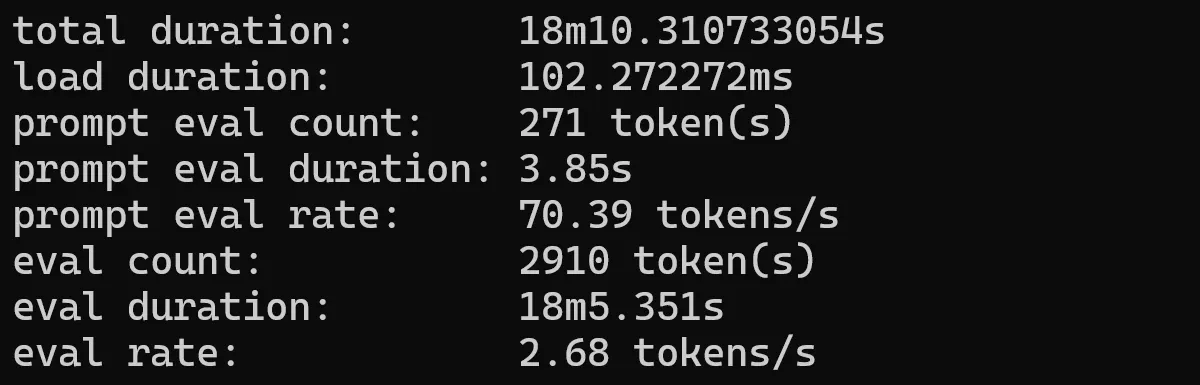
Now we’re looking at… pretty slow. This is to be expected. If you’re looking for real-time fast chat-type applications, it’s best to stick with the smaller models.
Let’s check out some other models.
Gemma2
Google’s Gemma 2 model is available in three sizes, 2B, 9B and 27B, featuring a brand new architecture designed for class leading performance and efficiency.
ollama run gemma2:2b --verbose
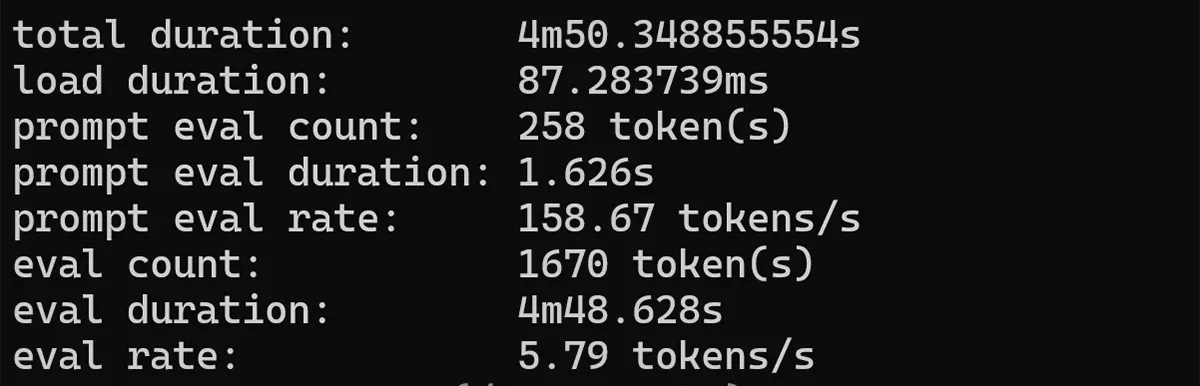
Phi3 3.5b
Phi-3 is a family of lightweight 3B (Mini) and 14B (Medium) state-of-the-art open models by Microsoft.
ollama run phi3:latest --verbose
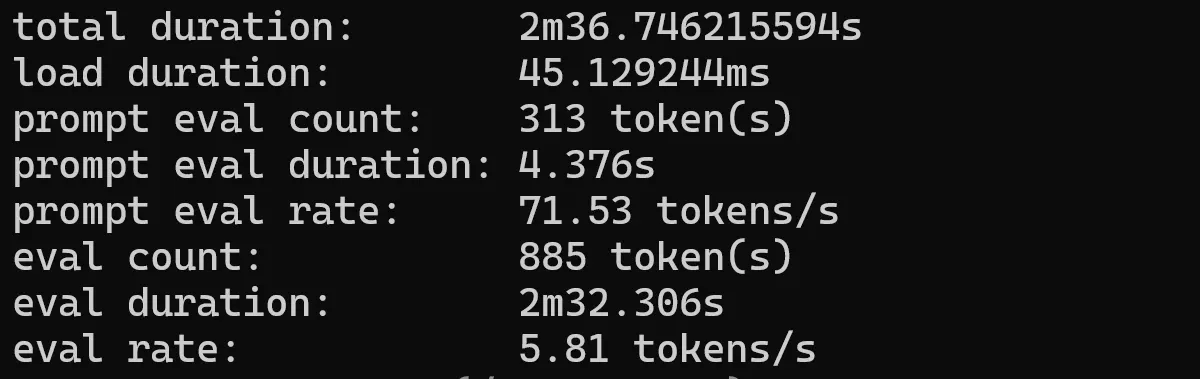
QWEN 0.5b
Qwen is a series of transformer-based large language models by Alibaba Cloud, pre-trained on a large volume of data, including web texts, books, code, etc.
ollama run qwen:0.5b --verbose
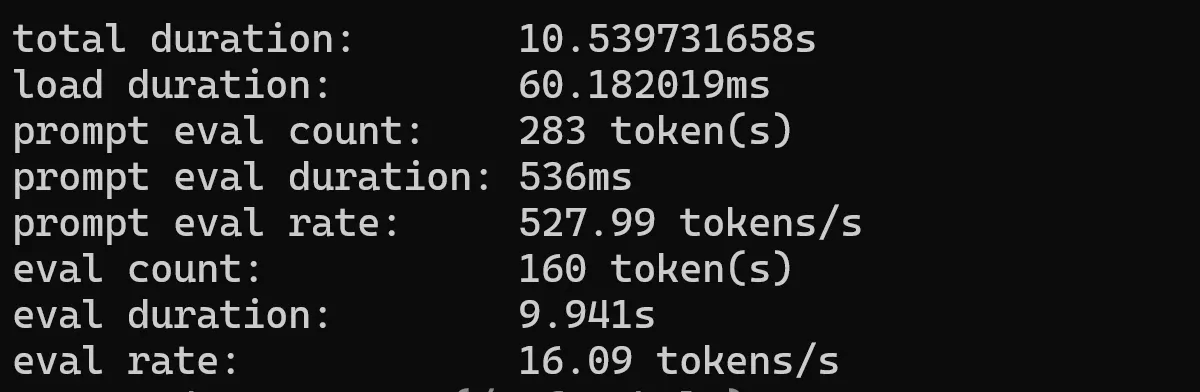
QWEN 1.8b
ollama run qwen:1.8b --verbose
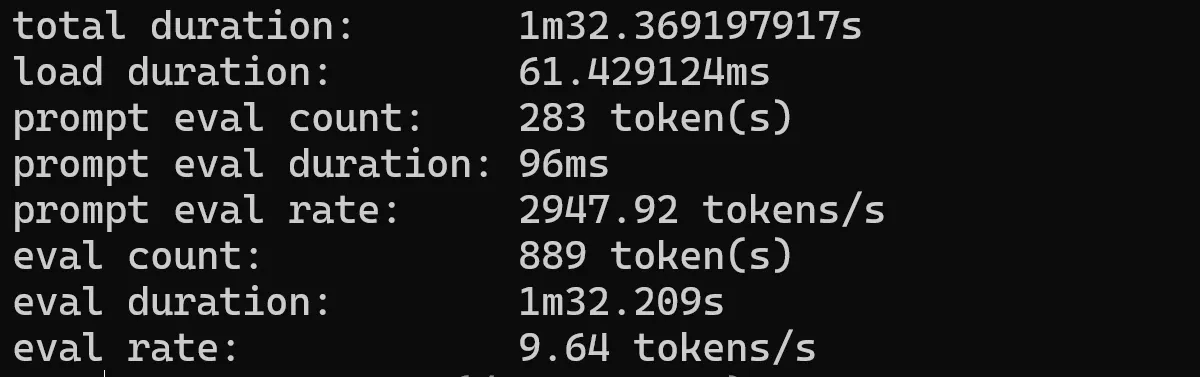
QWEN 4b
ollama run qwen:4b --verbose
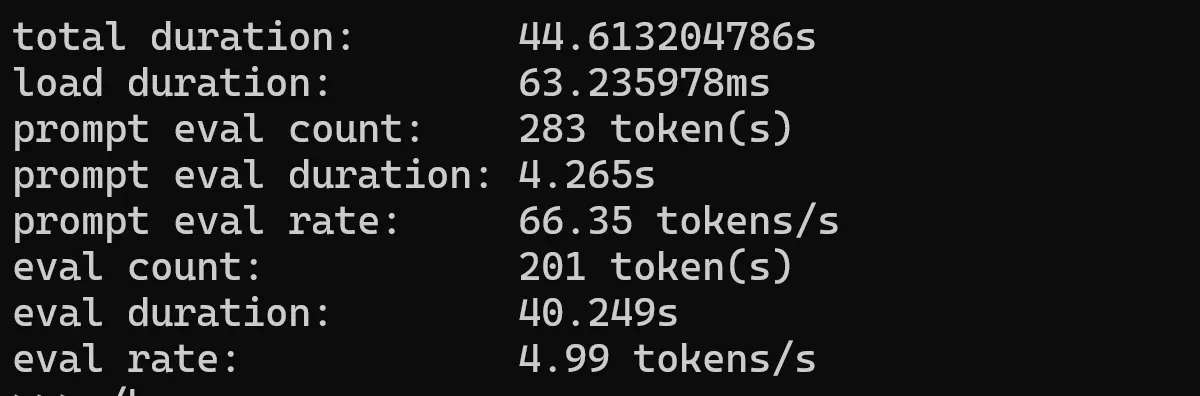
Llama 3.2 1b
The Meta Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
Meta’s Llama 3.2 goes small with 1B and 3B models.
ollama run llama3.2:1b --verbose
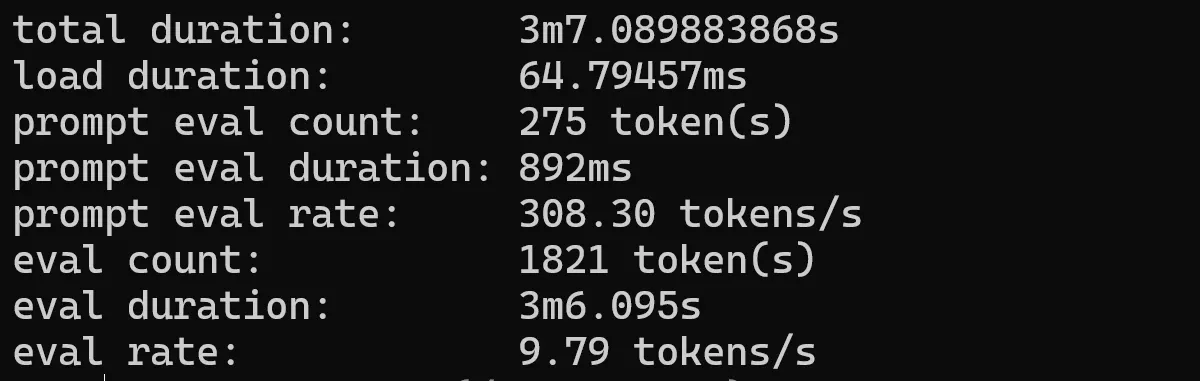
Llama 3.2 3b
ollama run llama3.2:latest --verbose
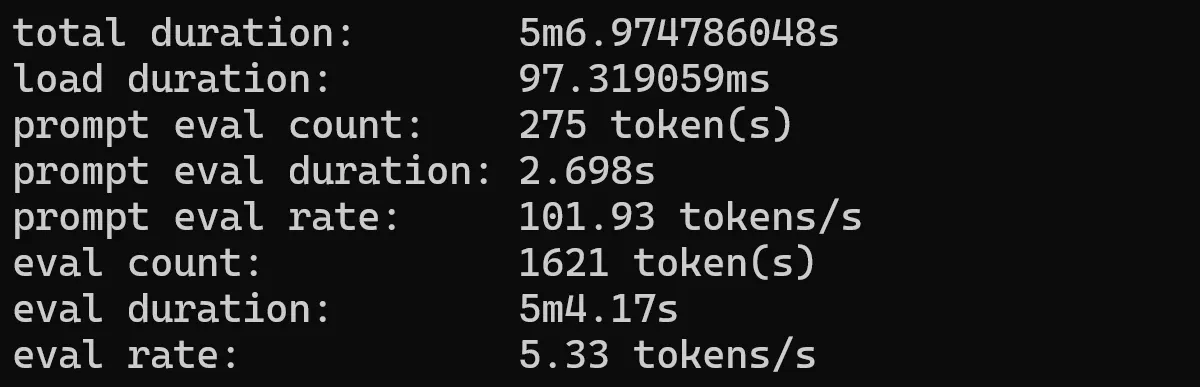
Gemma 2b
Gemma is a family of lightweight, state-of-the-art open models built by Google DeepMind. Updated to version 1.1
ollama run gemma:2b --verbose
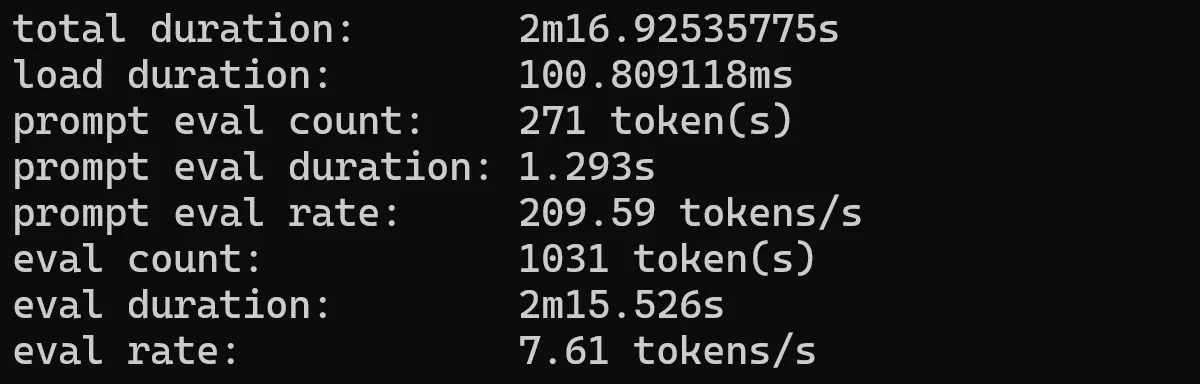
qwen 2.5
Qwen2.5 models are pretrained on Alibaba’s latest large-scale dataset, encompassing up to 18 trillion tokens. The model supports up to 128K tokens and has multilingual support.
qwen 2.5 .5b
ollama run qwen2.5:0.5b --verbose
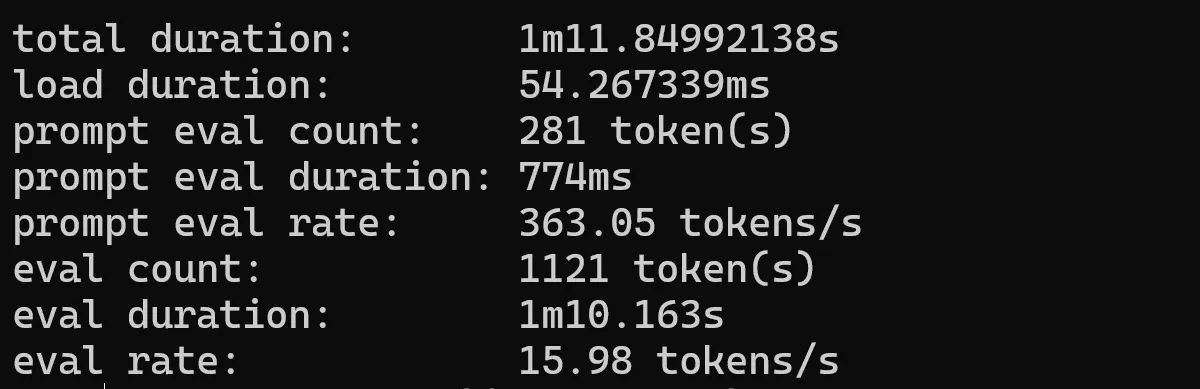
Note: the 1.5b and 3b models go into an “endless loop” with this prompt. I’ll look into this later.
qwen 2.5-coder
The latest series of Code-Specific Qwen models, with significant improvements in code generation, code reasoning, and code fixing.
qwen 2.5-coder 0.5b
ollama run qwen2.5-coder:0.5b --verbose
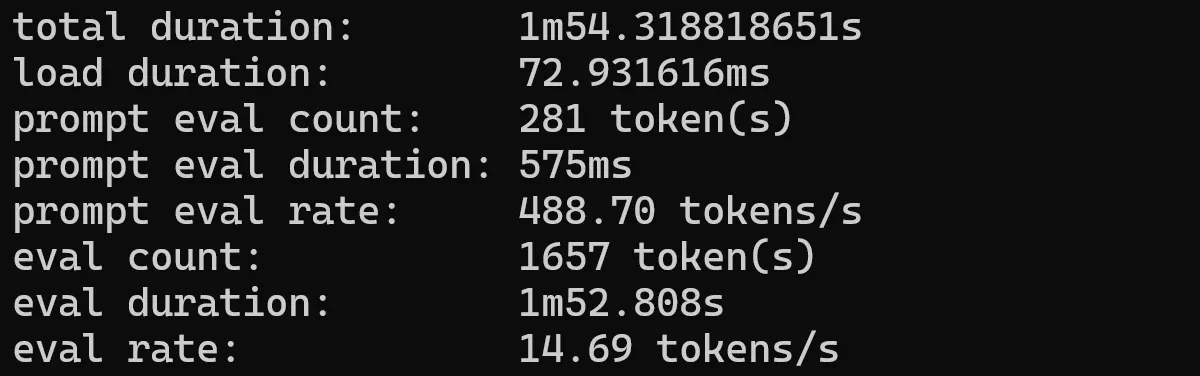
qwen 2.5-coder 1.5b
ollama run qwen2.5-coder:1.5b --verbose
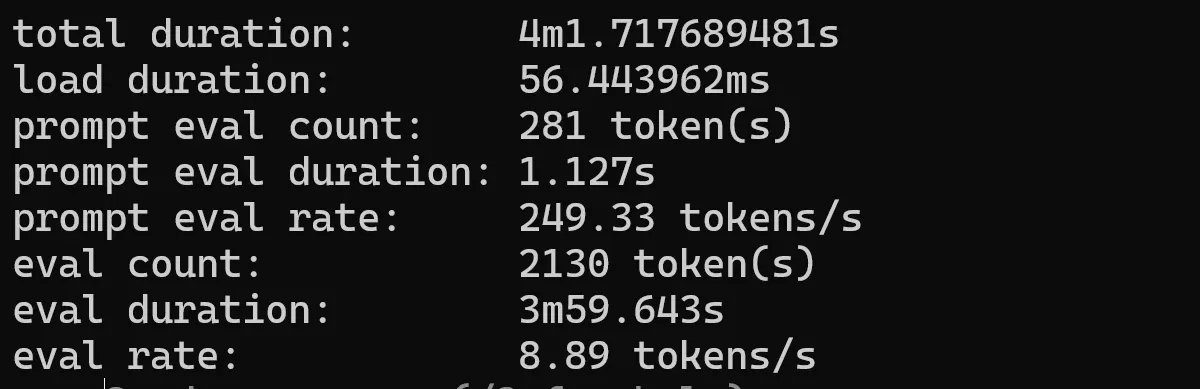
tinyllama
The TinyLlama project is an open endeavor to train a compact 1.1B Llama model on 3 trillion tokens.
ollama run tinyllama --verbose
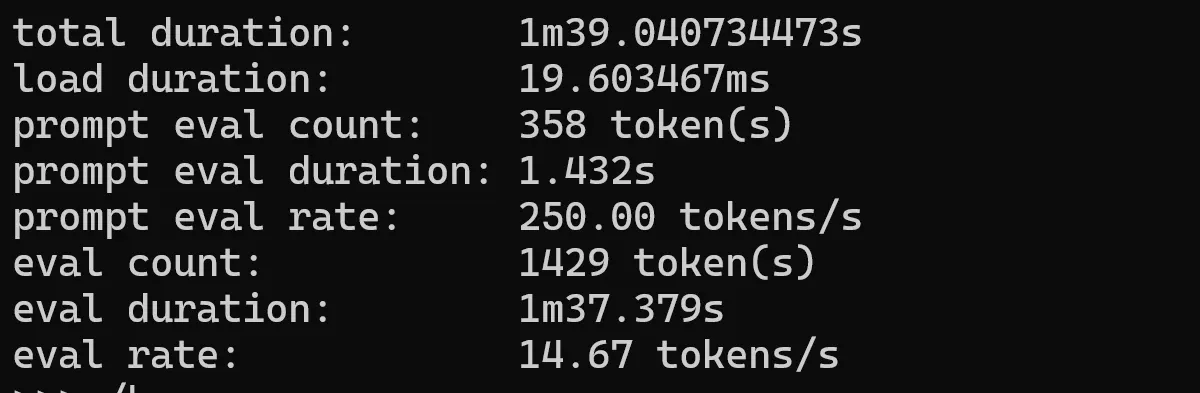
orca-mini
A general-purpose model ranging from 3 billion parameters to 70 billion, suitable for entry-level hardware.
ollama run orca-mini --verbose
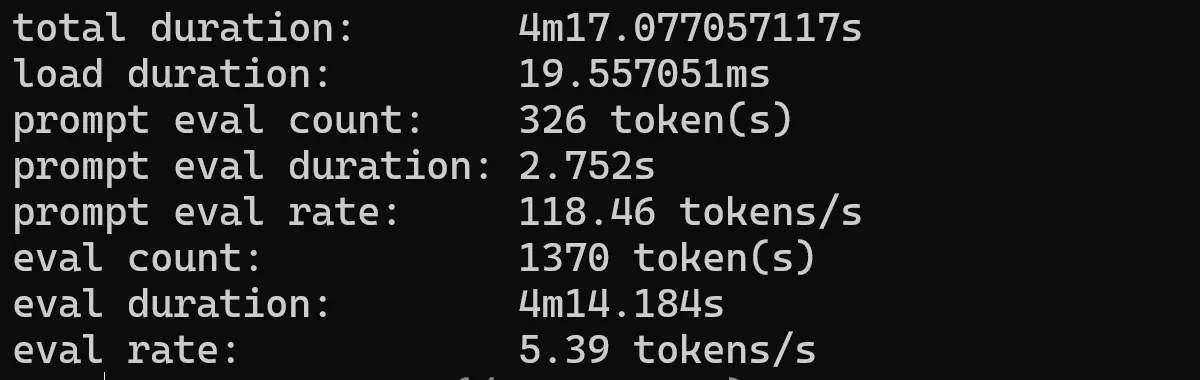
tinydolphin
An experimental 1.1B parameter model trained on the new Dolphin 2.8 dataset by Eric Hartford and based on TinyLlama.
ollama run tinydolphin --verbose
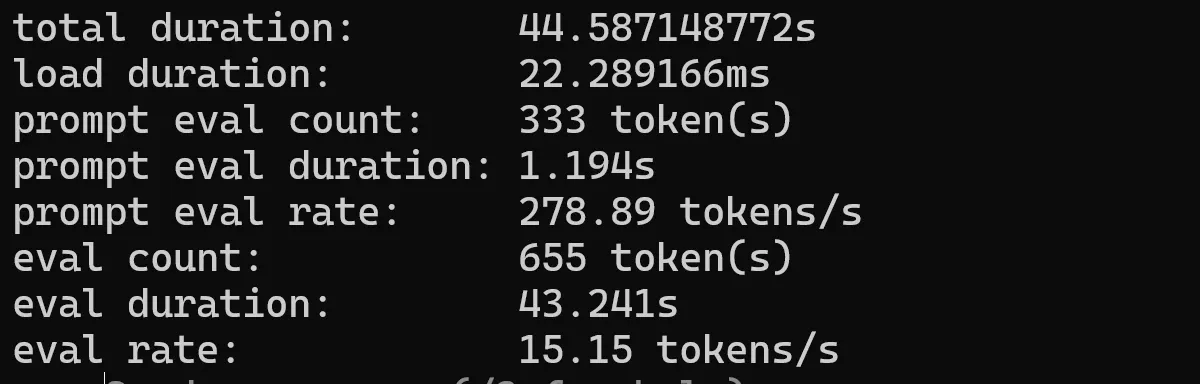
smollm
A family of small models with 135M, 360M, and 1.7B parameters, trained on a new high-quality dataset.
ollama run smollm --verbose
Conclusion
So here’s a bar graph of the results. If you want the CSV file, you can download it here.
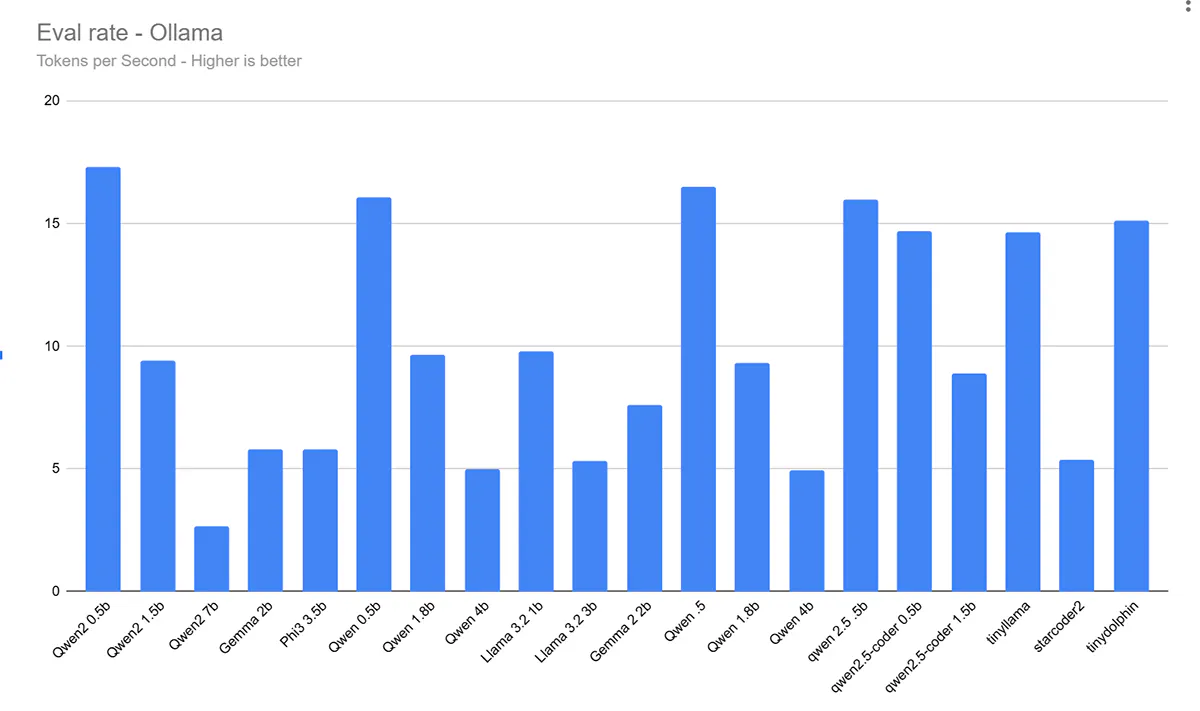
Most of these models performed well. I know that LLMs and Ollama aren’t the only use cases of these devices, but I have been asked several times after doing some tests and decided to spend a few hours on these tests so you can get a good idea of how they perform.
If you have any comments or questions Yell at me!

Skip the hype. The newsletter that keeps you in the know.
AI news curated for engineers. The AI New Hotness Newsletter is what you need.
Zero fluff. Just the research, tools, and infra updates that actually affect your production stack.
Stay up to date on AI for developers - Subscribe on LinkedIn