


Hey AI, Write Like Me

Jeremy Morgan 
Oct 13, 2024 - 10 min read
Last Update: Oct 13, 2024

I wrote a book! Check out A Quick Guide to Coding with AI.
Become a super programmer!
Learn how to use Generative AI coding tools as a force multiplier for your career.
When I write, I’m always looking for ways to make writing easier while still keeping my own style. I started an experiment not long ago to see if I could teach AI models to write effectively in my style.
This piece will explain how I used my own blog posts as training data to make custom AI writing assistants. We’ll talk about the technical side of collecting material, the problems I ran into, and my first thoughts on the end result. You will learn about the pros and cons of personalized AI writing models, whether you are a writer who wants help from AI or a developer who wants to learn more about natural language processing.
Here’s the Custom GPT I created, which is what this article is about.
How I Trained ChatGPT to write like me
So, starting out, I thought the best way to feed information into ChatGPT or Claude about my writing was to create a custom GPT, instruct it to look at my sample writing on this blog, and then generate text that sounds like it was written by me.
I figured PDFs would be a good way to start. They feature my writing fresh from the page and are good for analysis. This was a terrible choice, and you’ll soon see why. But here is the initial plan.
Write a script to:
- Get every URL from my website (from a sitemap)
- Visit each URL and generate a .PDF for it
Sounds simple enough. Let’s dig in.
Getting a Site Map
The first thing I need to do is get my site map. This is the best way to get a solid list for URLs for my site.
So I’ll download that:
wget https://www.jeremymorgan.com/sitemap.xml
Now I have a sitemap, but it’s a big bunch of XML.
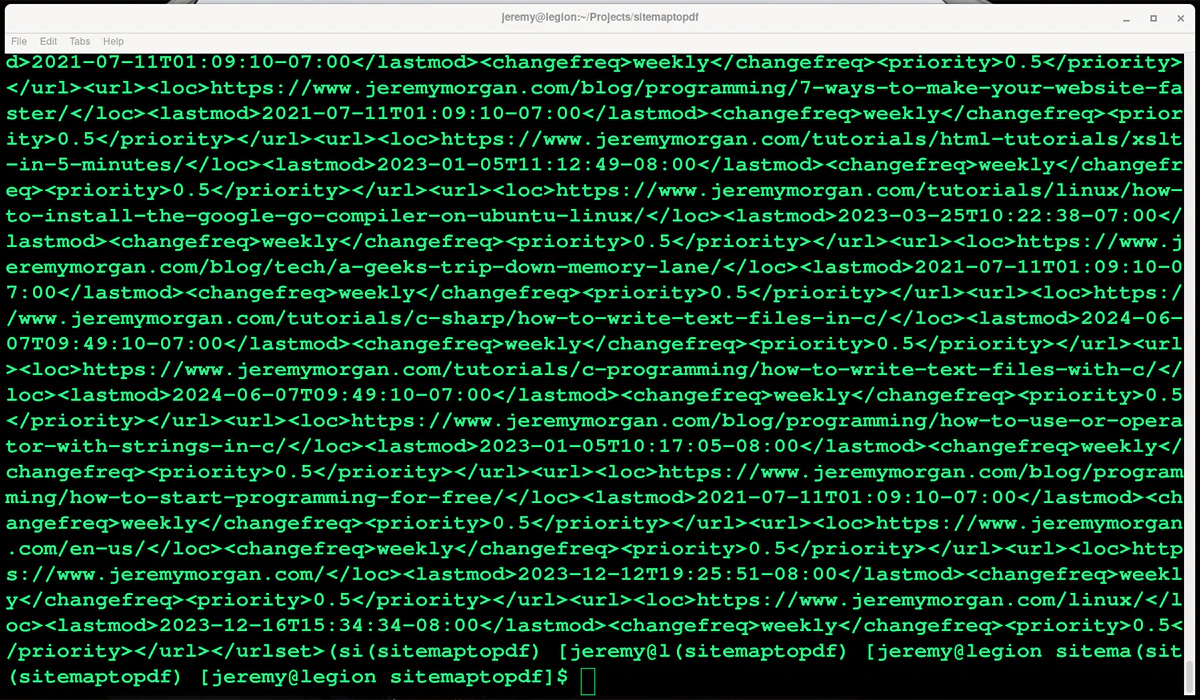
Let’s create a Python app to rip the URLs out, and then we’ll crawl them.
I’ll create a new directory:
mkdir sitemaptopdf && cd sitemaptopdf
create a Python virtual environment:
python3 -m venv sitemaptopdf
source sitemaptopdf/bin/activate
Now, I’ll create a main.py file that will be our script for getting PDFs of all my articles.
Right now, my main.py looks like this:
def main():
# do stuff
if __name__ == "__main__":
main()
Parsing the Site Map
Let’s create a function to parse that sitemap and write all the URLs to a list. I will write it to a text file so we can pull out the URLs we don’t want included.
At the top of the file we’ll add:
import xml.etree.ElementTree as ET
import re
And then we’ll create a function to rip those URLs out:
def extract_urls_from_sitemap(sitemap_path, output_path):
# Parse the XML file
tree = ET.parse(sitemap_path)
root = tree.getroot()
# Extract URLs
urls = []
for url in root.findall('.//{http://www.sitemaps.org/schemas/sitemap/0.9}loc'):
urls.append(url.text.strip())
# Write URLs to text file
with open(output_path, 'w') as f:
for url in urls:
f.write(f"{url}\n")
print(f"Extracted {len(urls)} URLs and saved to {output_path}")
And in our main function, we’ll add this:
def main():
sitemap_path = 'sitemap.xml'
output_path = 'extracted_urls.txt'
extract_urls_from_sitemap(sitemap_path, output_path)
Now, we’ll run it and see if works:

No errors so far lets look at extracted_urls.txt
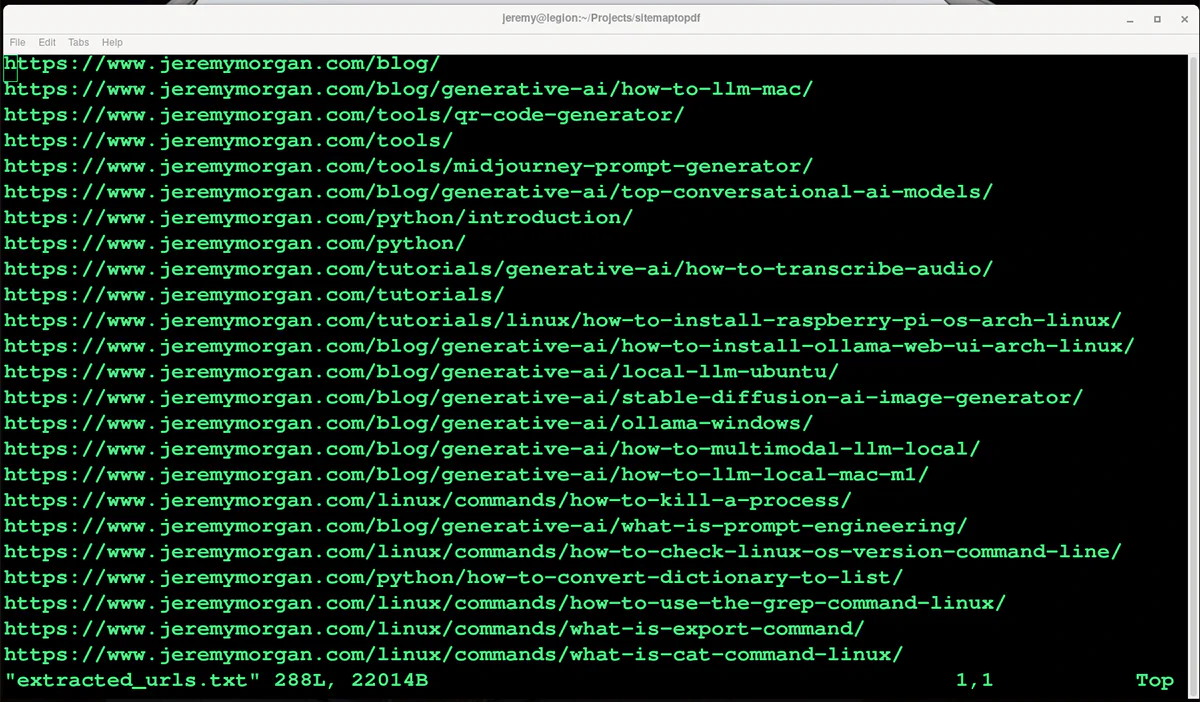
Perfect. Now I can strip the urls I don’t want out of the text, like jeremymorgan.com/python for instance. I want only full articles. So I got it down to a cool 255 articles. Should be enough to give the model some idea what I what I write like.
Now that I’ve done that we need to build a crawler.
Crawl the URLs and Make PDFs
We will need requests and weasyprint to make this work.
pip install requests weasyprint
Add them in at the top of the file:
import requests
import os
from weasyprint import HTML
from urllib.parse import urlparse
This function will visit each page and print it to a pdf file.
def urls_to_pdfs(input_file, output_folder):
# Ensure the output folder exists
os.makedirs(output_folder, exist_ok=True)
# Read URLs from the input file
with open(input_file, 'r') as f:
urls = f.read().splitlines()
# Process each URL
for url in urls:
try:
# Extract the last folder name from the URL
parsed_url = urlparse(url)
path_parts = parsed_url.path.rstrip('/').split('/')
last_folder = path_parts[-1] if path_parts else 'index'
# Generate a filename for the PDF
filename = f"{last_folder}.pdf"
pdf_path = os.path.join(output_folder, filename)
# Convert HTML to PDF using WeasyPrint
HTML(url=url).write_pdf(pdf_path)
print(f"Converted {url} to {pdf_path}")
except Exception as e:
print(f"Error processing {url}: {str(e)}")
and finally, we need to call it our main method:
sitemap_path = 'sitemap.xml'
urls_file = 'extracted_urls.txt'
pdf_folder = 'pdf_output'
# Extract URLs from sitemap
extract_urls_from_sitemap(sitemap_path, urls_file)
# Convert URLs to PDFs
urls_to_pdfs(urls_file, pdf_folder)
Now it’s ready to run!
Getting the PDFs
Woo-hoo, looks like it worked. It ran surprisingly fast, and now I have a big pile of PDFs to work with:
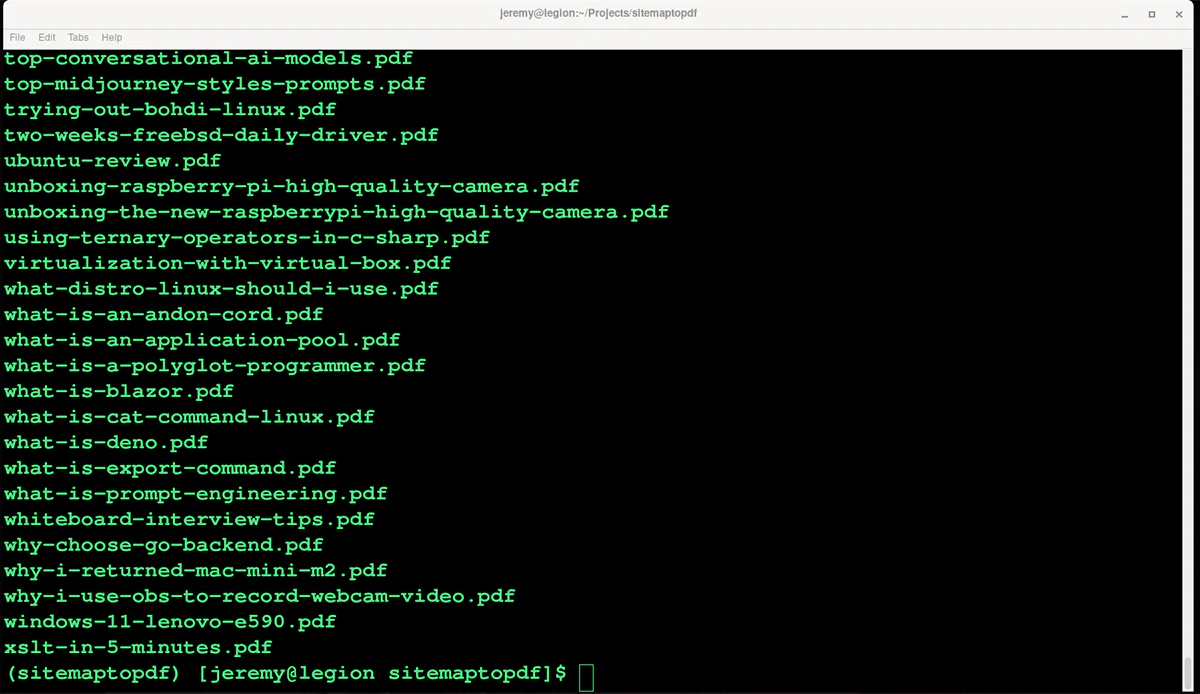
I also did a quick spot check of a few of them, and they look pretty good.
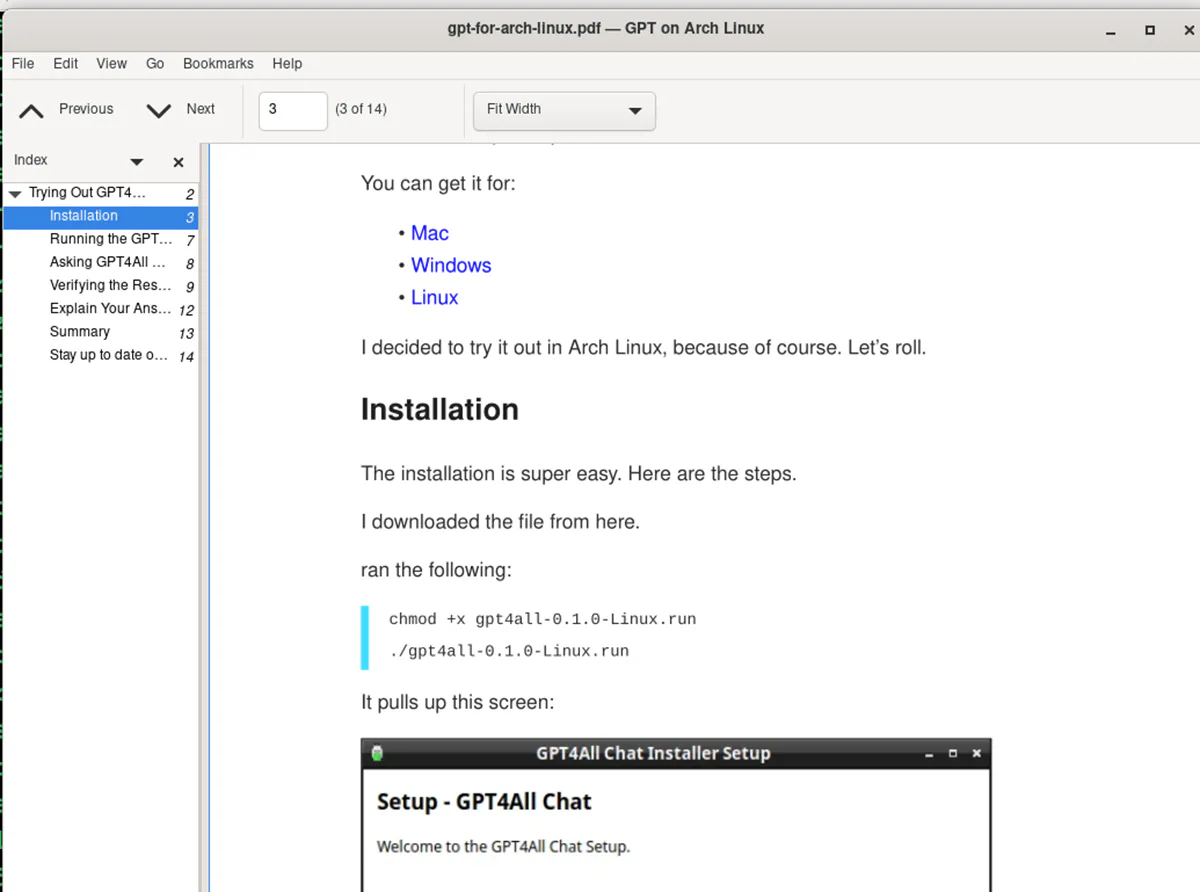
Let’s build some stuff with this.
By the way here’s a link to the source code if you want to use it.
Creating a Custom GPT on ChatGPT
So now I’ll go to my ChatGPT custom GPTs and select “Create a GPT”.
Make an agent who writes exactly like Jeremy Morgan. Write in the same voice and style, and mimic any unique expressions or writing patterns. Write in the same manner so it's exactly as if Jeremy wrote it himself. I will attach a sample of articles for you to to analyze to get an idea of how he writes.
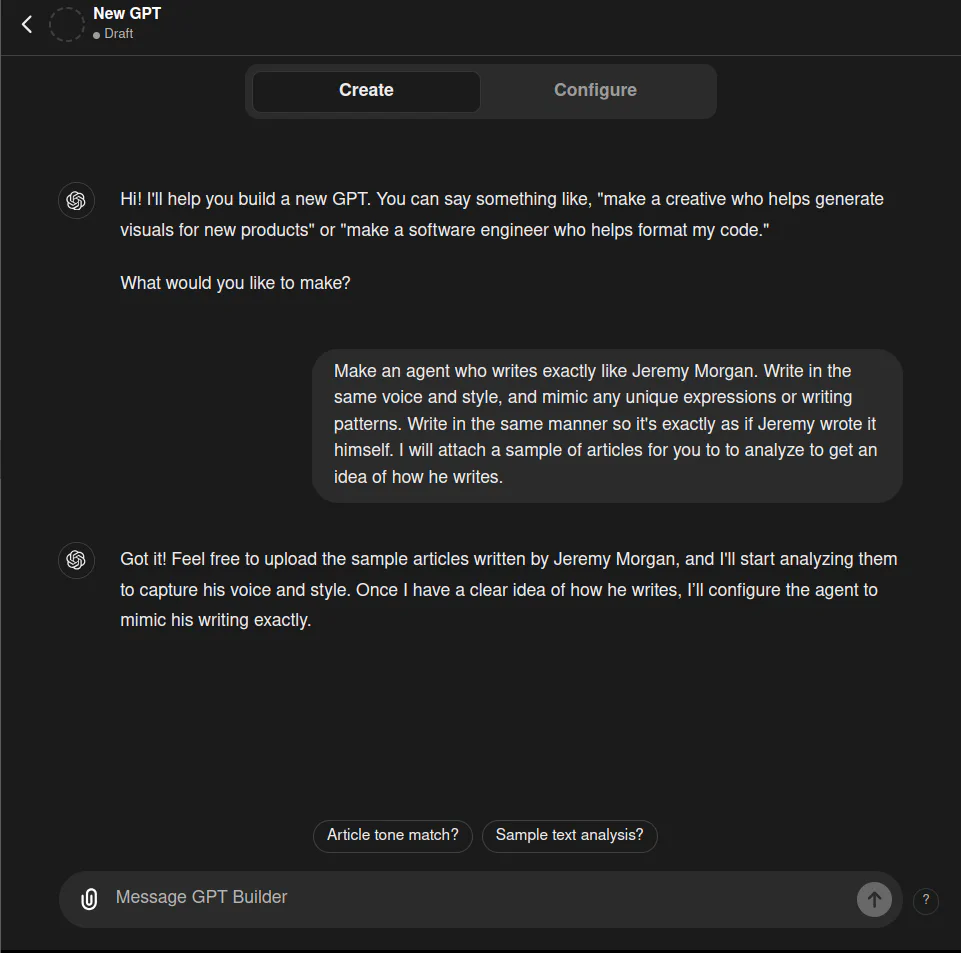
But one thing I hadn’t considered
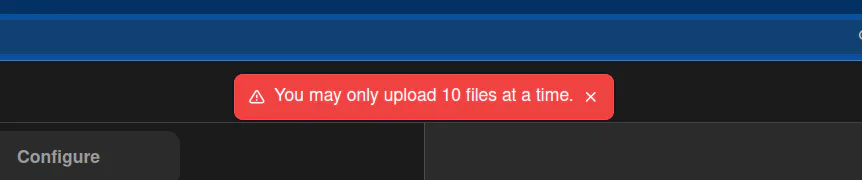
This is going to be fun!
After the first 10 files, it immediately analyzed my writing:
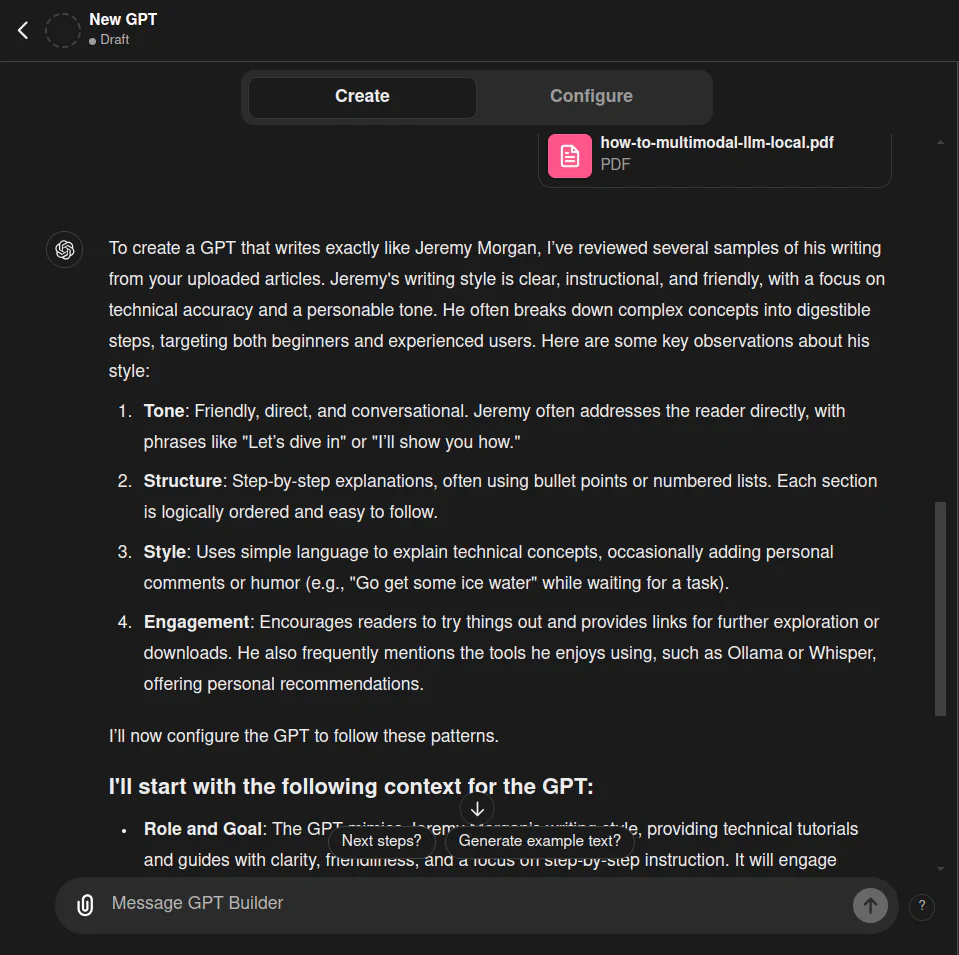
I have many more files to upload. 245 more.
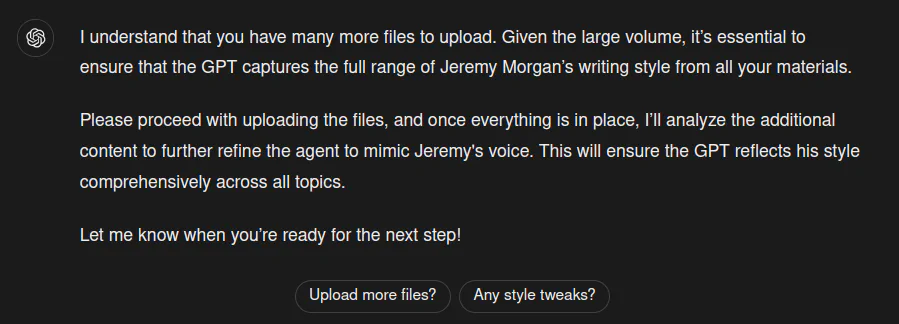
Awesome, so then I ran into a problem:
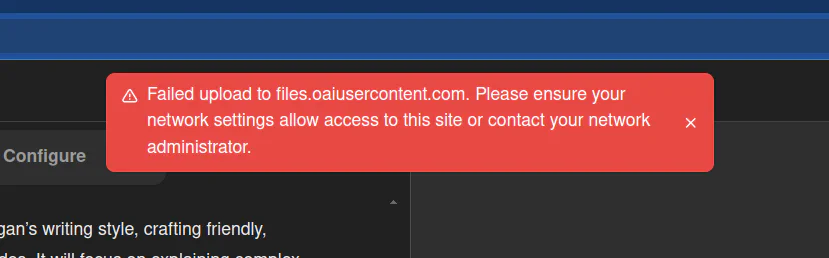
OpenAI might have an issue with me force-feeding a bunch of files.
Now, I think my best bet would have been to upload my favorite articles or ones that most match my style. I was only able to upload 40 PDFs, so I’ll delete one and start another one. But since I uploaded so much, OpenAI gave me a two-hour timeout.
So then I thought, “Heck, why even use PDFs at all?” I have a bunch of markdown files from my site. The PDF solution is a good one, but it is clearly too big.
What if I build a giant markdown file and upload that?
Shifting Gears
Now I know what I have to do. I need to combine all of the markdown files I use to build my website. It should be easy enough with a little Python, right?
I created a new project named Markdownsmash.
One problem is that the content is spread out into various folders.
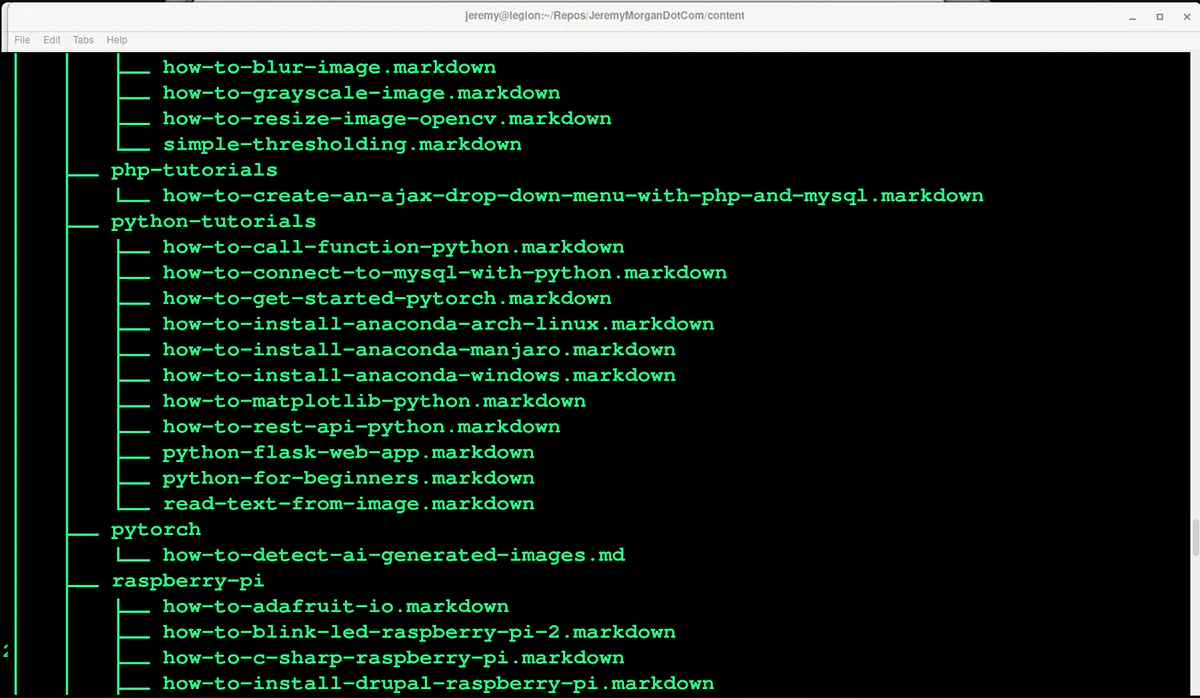
So, I copied my /content directory from my folder and added it to my project.
Now, I’ll write a separate script to find all those markdown files. I’ll name process-markdown.py
The first step is to create a function that will find all my Markdown files and count them.
import os
def find_markdown_files(directory):
markdown_files = []
file_count = 0
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(('.md', '.markdown')):
markdown_files.append(os.path.join(root, file))
file_count += 1
print(f"Found file {file_count}: {os.path.join(root, file)}")
return markdown_files, file_count
content_directory = './content'
markdown_files, total_files = find_markdown_files(content_directory)
print(f"\nTotal markdown files found: {total_files}")
I run it it shows that I have 306 files. This makes sense because there are a lot of indexes, and some other files in there that are cluttering it up. So I went in and removed a bunch by hand.
And hey, whaddya know we have 255 again. Great!

So now I need to build a function to read the markdown files. However, I don’t want any header information, so I’ll strip that out. I’ll also strip anything that starts with title, headline, description, etc.
def read_markdown_content(file_path):
content = []
header_fields = ['headline:', 'date:', 'draft:', 'section:', 'description:']
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
if not any(line.lower().startswith(field) for field in header_fields):
content.append(line)
return ''.join(content).strip()
This works great. So now I’ll attempt to combine them all into a single markdown file. Hopefully, it’ll be less than 10MB, and I’ll upload that to ChatGPT.

It ran successfully, and wow, 1.6MB and 41,309 lines of text. This should be plenty. It’s smaller than a single PDF for an article, so this should work much better.
Here’s a link to the source code to see the final result.
Creating another Custom GPT
This time, I’ll create one from my Markdown file. It’s a simple upload, and I’ll provide some instructions.
Here’s what I added:
You should write articles and tutorials indistinguishable from my own writing, targeting technical professionals, programmers, and fans of JeremyMorgan.com.
Instructions:
Analyze Provided Writing Samples:
Content Themes: Note the specific subjects and topics I cover.
Vocabulary: Identify technical terms, jargon, and phrases I commonly use.
Style and Tone: Observe the level of formality, use of humor, and overall voice.
Sentence Structure: Examine the complexity and length of my sentences.
Punctuation and Formatting: Look at my use of punctuation, headings, bullet points, code snippets, etc.
Narrative Flow: Understand how I introduce topics, develop ideas, and conclude articles.
Engagement Techniques: Note how I interact with the reader through questions, prompts, or calls to action.
Figurative Language and Personal Touches: Identify any metaphors, anecdotes, or personal insights I include.
Generate Content:
Use the analyzed elements to create new articles and tutorials on the provided list of subjects.
Ensure the writing resonates with technical audiences and maintains consistency with my established style.
I uploaded my Markdown file, and it’s ready to go!
I asked it to write an article about setting up Python in Linux, and it looks like something I’d write.
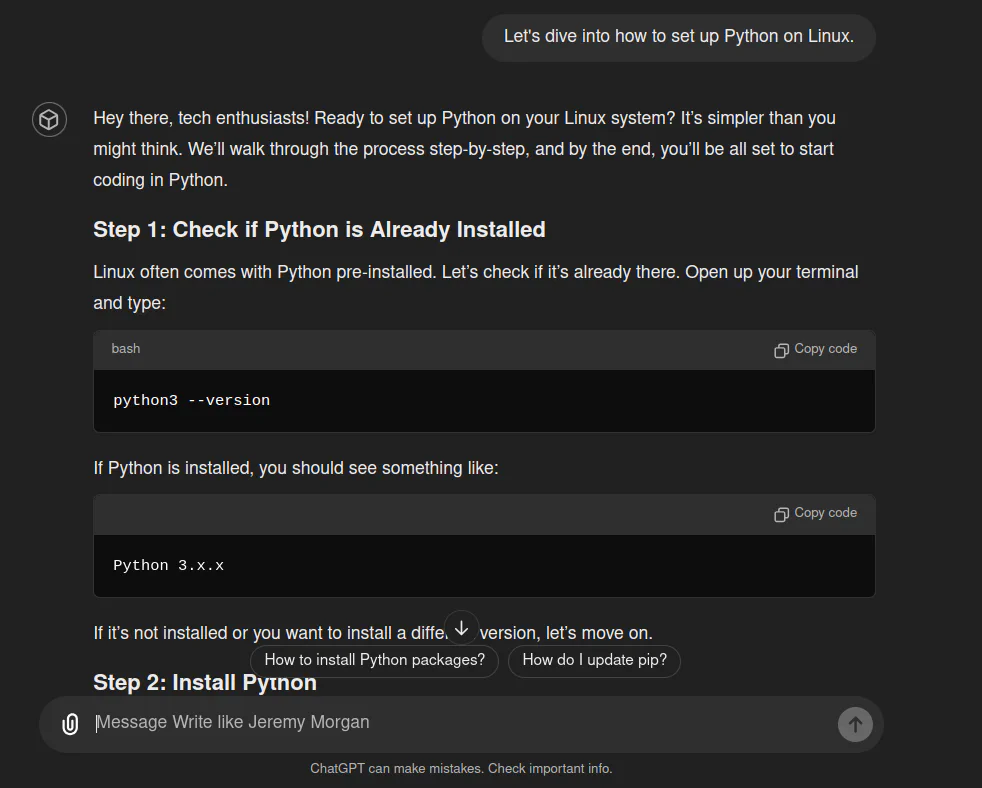
But this is a simple tutorial; it’s kind of hard to mess that up. Let’s try something more creative.
Write a blog post titled "Why you should learn Python today"
After I sent this in, it created an article. It looks like something I would write, but a little “extra”—more enthusiasm and cheesiness. Maybe I could use that.
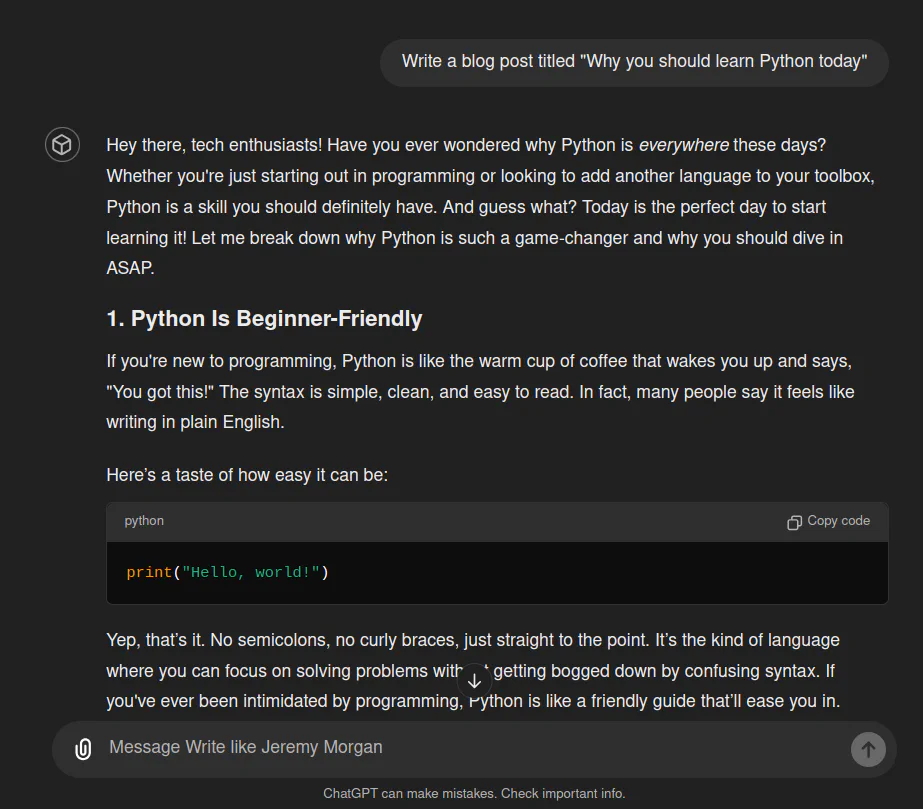
So this is great, and I’ll try it out again. I made this GPT public just for readers of this blog (not sure why anyone would actually use it) if you want to check it out here.
Claude
What are projects?
So I’ll go to Claude and create a new project.
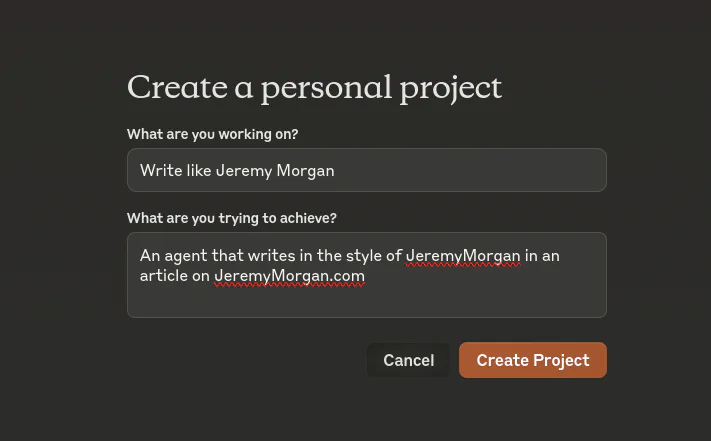
Now we have another problem.
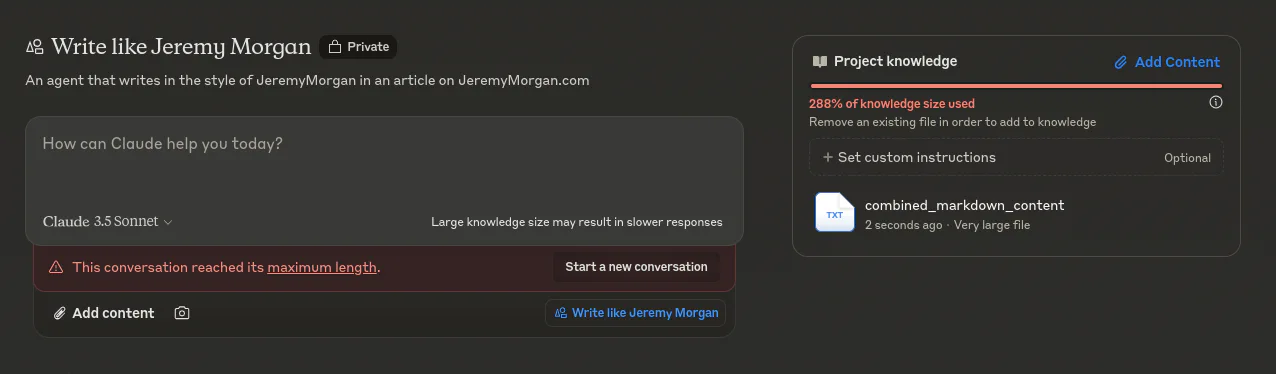
oops, the file is too big. Well I know there’s some wasteful stuff in it.
So I refactored the function to read the markdown and removed way more stuff, but that didn’t help.
I tried removing tons of irrelevant content, images, etc., but nothing worked. So, I uploaded a handful of markdown files from the website. It’s definitely not the same amount of sampling, but hopefully, it will work.
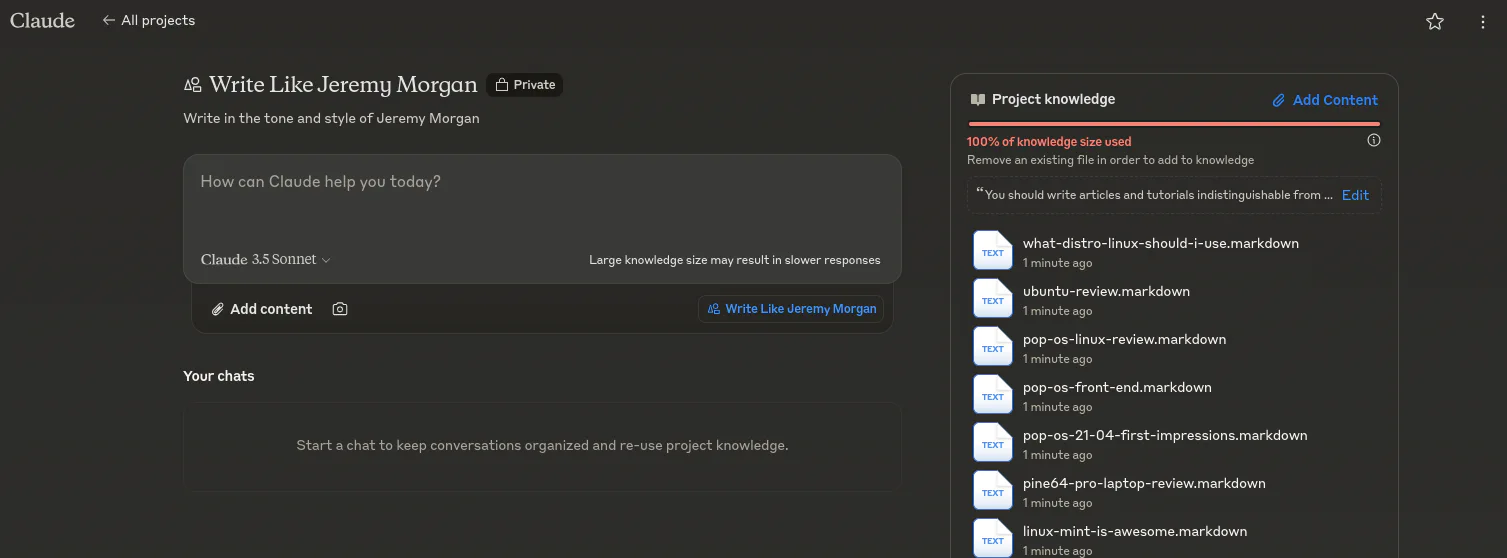
Then I sent it with the same prompt.
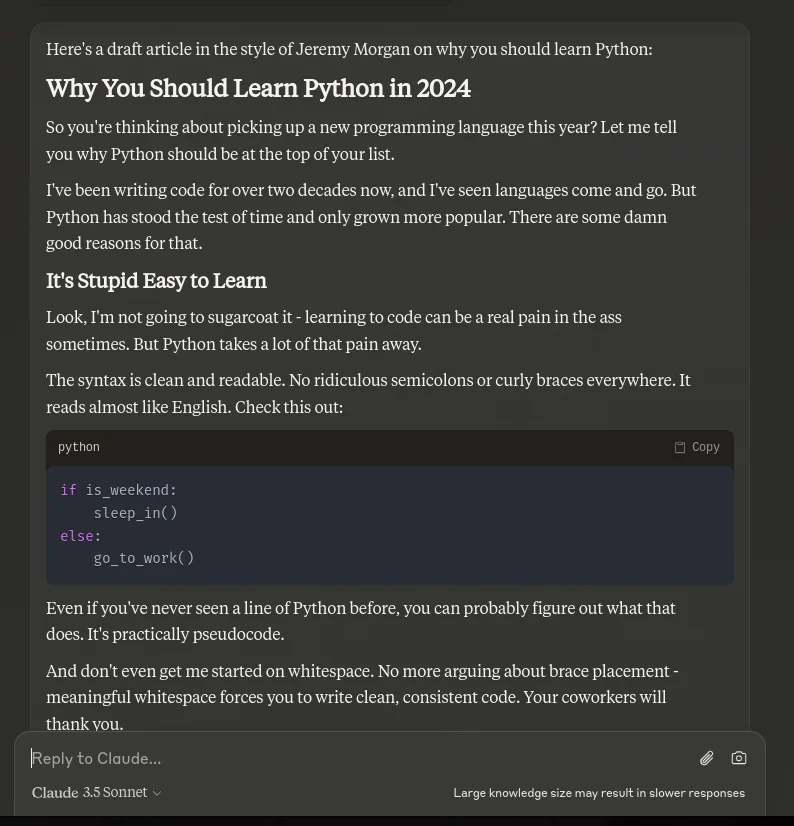
So it does sound a bit like me, with more cursing. Don’t get me wrong, I’m not above throwing out some curse words, but I try not to on this website to keep it 100% family-friendly. So, there was nothing in the training that indicated that this should happen. Oh well.
I’ll do some more experiments with it for sure.
Conclusion
Diving into this was pretty fun. I documented my process of creating custom GPTs trained on my own blog content. I started by extracting URLs from my sitemap and converting blog posts to PDFs, but I ran into file size limitations when using ChatGPT. Pivoting to a markdown-based approach, I successfully created a custom GPT model that emulates my writing style. I also experimented with Claude AI, though with more limited training data. This is all still a work in progress.
The results are interesting. While the models captured some elements of my voice and topic expertise, they also introduced quirks like increased enthusiasm or unexpected language choices. This experiment highlighted both the potential of personalized AI writing assistants and their current limitations. Moving forward, I will continue refining these models and checking the results.
Have you done anything like this? Want to share? Yell at me!!
